
-
Contents
-
2. Maps for Global Localization
-
2-1. Keyframe-based Submap
-
2-2. Global Feature Map
-
2-3. Global Metric Map
-
3. Single-shot Global Localization: Place Recognition and Pose Estimation
-
3-1. Place Recognition Only
-
3-2. Place Recognition Followed by Local Pose Estimation
-
3-3. Pose Estimation-coupled Place Recognition
-
3-4. One-Stage Global Pose Estimation
-
4. Sequential Global Localization
-
4-1. Sequential Place Matching on keyframe-based submaps
-
4-2. Sequential Metric Global Localization
-
5. LiDAR-aided Cross-robot Localization
-
5-1. LiDAR-aided Multi-robot System
-
5-2. Cross-robot Back-end
-
6. Open Problems
-
6-1. Evaluation Difference
-
6-2. Multiple Modalities
-
6-3. Less Overlap
-
6-4. Unbalanced Matching
-
6-5. Efficiency and Scalability
-
6-6. Generalization Ability
-
7. Conclusion
LiDAR Localization 관련해서 서칭하다가, 이 분야 유명하신 학자가 포함된 survey를 발견해서, 이를 토대로 견식을 쌓고자 한다!
이 글은 학부생이 공부를 목적으로 작성한 요약, 정리이므로,
오타 혹은 바로잡을 사항이 있다면, 언제든 코멘트는 환영입니다!

Contents
1. Introduction
1-1. Problem Formulation and Paper Organization
1-2. Typical Situations
1-3. Relationship to Previous Surveys
2. Maps for Global Localization
2-1. Keyframe-based Submap
2-2. Global Feature Map
2-3. Global Metric Map
3. Single-shot Global Localization: Place Recognition and Pose Estimation
3-1. Place Recognition Only
3-2. Place Recognition Followed by Local Pose Estimation
3-3. Pose Estimation-coupled Place Recognition
3-4. One-stage Global Pose Estimation
4. Sequential Global Localization
4-1. Sequential Place Matching
4-2. Sequential Metric Localization
5. LiDAR-aided Cross-robot Localization
5-1. LiDAR-aided Multi-robot System
5-2. Cross-robot Back-end
6. Open Problems
6-1. Evaluation Difference
6-2. Multiple Modalities
6-3. Less Overlap
6-4. Unbalanced Matching
6-5. Efficiency and Scalability
6-6. Generalization Ability
7. Conclusion
2. Maps for Global Localization
Global Localization을 위한 지도를 소개하며,
일반적으로 사용되는 지도를 3가지 기본 클러스터로 분류('키프레임 기반 서브맵, 글로벌 피쳐 맵, 글로벌 매트릭 맵)하여 설명
2-1. Keyframe-based Submap
대규모 환경에서 특히 사용,
각 키프레임은 '로봇의 포즈'와 '정렬된 서브맵', 그리고 키프레임 간의 topological 혹은 geometrical 연결 형태의 추가 정보로 구성된다.
Keyframe-based submap은 유지하기 쉽고, downstream navigation task(* 최종 해결하고자 하는 작업)에 적합하다.
2-2. Global Feature Map
환경을 설명하기 위해, sparse한 local feature point를 유지하며, HD map과 같은 방법을 통해 자율주행차량에 사용된다.
2-3. Global Metric Map
밀집된 metric 표현으로, 작업 환경을 설명하며, 이는 자원 제약이 있는 모바일 로봇에게는 부담이 될 수 있다.
3. Single-shot Global Localization: Place Recognition and Pose Estimation

3-1. Place Recognition Only
장소 인식만으로 가장 유사한 장소를 검색하는 방법을 다룬다.
3-1-1. Dense Points or Voxels-based
장소 인식만으로 접근하는 방식은 사전에 구축된 KeyFrame 기반의 Map에서 장소를 추출하여, 전역 위치 지정 문제를 해결한다.
LiDAR 장소 인식에서의 가장 큰 과제는 'global descriptor' 추출로, 이는 원시 point Cloud가 텍스처가 없고 불규칙하여 처리하기 어렵기 때문이다.
Dense Points or Voxels-based 방법은 밀집된 표현에서 직접 global descriptor를 생성하며, 초기 laser scanner는 로봇 위치 지정을 위해 2D laser point만 제공한다. ?
3D Point cloud 작업을 위한 PointNet과 같은 새로운 인코더는 성능 향상을 가져왔고,
Transformer 구조가 등장하면서, 장소 인식에서 중요한 지역 특성을 선택하는 데 주목받고 있다.
또한, 3D Point cloud를 정규화하기 위해 복셀화 절차를 사용하여 전역 설명자를 추출하는 과정도 보편화되고 있다. [8]
3-1-2. Sparse Segements-based
포인트 세그먼트를 기반으로 장소 인식을 수행하는 방법이다.
Seed는 원시 Point Cloud를 segment 객체로 나누고, 이 객체의 위상적 정보를 서술자에 인코딩한다.
SGPR은 원시 Point Cloud의 의미론적 및 위상적 정보를 활용하여, 그래프 신경망을 사용해 의미 그래프 표현을 생성한다.
Locus는 일시적이고 위상적인 정보를 인코딩해서, 구별 가능한 장면 표현을 만든다.
이러한 segementation기반의 접근 방식은 인간의 장소 인식 방법에 가까우며, 고수준 표현을 사용하는 경향이 있다.
따라서, segementation의 품질과 추가적인 의미 정보에 크게 의존하며, 3D Point Cloud segementation은 보통 시간과 자원을 많이 소모한다. [9]
3-1-3. Projection-based
3D Point Cloud를 2D 평면에 사영시킨 후, global descriptor를 추출한다.
M2DP(He et al.)은 원시 포인트 클라우드를 여러 2D 평면에 사영하여, 다양한 평면의 descriptor로 시그니처를 구성한다.
LiDAR Iris는 3D 포인트 클라우드의 높이 정보를 이진 LiDAR-Iris 이미지로 인코딩하고, 회전 불변성을 달성하기 위해 Fourier domain으로 변환한다.
Kong et al.은 포인트 클라우드를 의미 정보로 인코딩된 scan context 이미지로 변환하고, 회전 불변 표현을 학습하기 위한 네트워크를 설계했다.
전반적으로, 3D LiDAR 포인트 클라우드의 global descriptor 추출이 성공적인 수준에 도달했지만, 일반화 능력 등의 여러 과제가 남아있다. (6.6절)
3-2. Place Recognition Followed by Local Pose Estimation
장소 인식 후에, 로봇의 자세를 사용자 맞춤형 자세 추정기를 통해 추정하는 방법을 설명한다.
고정밀 변환 추정을 위한 로컬 포즈 추정 방법을 다룬다.
장소 인식과 독립적으로 수행되며, 전체 로컬라이제이션은 거친 방법에서 세밀한 방법으로 진행된다.
먼저, 키프레임 기반의 서브맵에서 장소 검색을 수행하고,
입력 LiDAR를 매핑 데이터에 맞춰 로컬 포즈 추정을 적용한다.
local pose estimation은 일반적으로 정확한 포인트 클라우드 등록을 통해 이루어지며,
포인트 클라우드 등록(Point cloud registration = scan matching)은 로보틱스와 컴퓨터비전에 인기있는 토픽으로, 오류 함수를 최소화하여 최적의 변환을 추정하는 것을 목표로 한다.
3-2-1. Correspondence-based
포인트 클라우드 정합의 Challenge와 해결 방법
ICP 알고리즘은 계산 효율성에도 불구하고, 노이즈와 외부 요인에 취약한 것으로 알려져있다.
Go-ICP는 글로벌 정합을 제공하지만, 리소스 한계가 있는 플랫폼에서는 비효율적이다.
최근 연구는 LiDAR와 2D image 기반 특징 추출에 집중하며, 딥러닝 기반 기법들이 주목을 받고 있다.
RANSAC 등의 방법이 외부요인을 극복하는 데 사용되며, TEASER와 같은 방법은 높은 신뢰성을 보인다.
특징 기반 및 강건한 추정자가 결합된 방법들이 정밀한 위치 추정을 가능하게 한다.
3-2-2. Correspondence-free
3-3. Pose Estimation-coupled Place Recognition
장소 인식과 자세 추정을 밀접하게 결합한 방법을 다루는데,
구체적으로 동일한 처리 파이프라인을 공유하여, 맵을 더 간결하고 파이프라인을 더욱 긴밀하게 만들어 준다.
3-3-1. 3-DOF pose stimation
3-DOF pose estimation은 주로 평면 표면에서 작동하는 모바일 로봇에 초점을 맞추며, 위치와 yaw 값을 포함한다.
이를 위해 다양한 방법론들이 제안되었는데, 특히 Scan Context++와 함께 세부적으로 향상시키기 위한 기법들이 있다.
또한, range 이미지의 오버랩 추정 및 향상된 효율성을 제공하는 여러 방법이 논의되었으며, 이는 3-DoF pose estimation에 중요한 역할을 한다. [13]
3-3-2. 6-DOF pose stimation
* 장소 검색을 사용하는 이전 2단계 파이프라인(3.1.)에 이어, 정밀한 포즈 추정(3.2.)에 이어 이 방법의 장점은 무엇인가?
(1) Lightweight map
(2) Geometric verification
(3) Initial guess for refinement : LCDNet에 따르면, 초기 추정은 ICP 등록 적용시 런타임과 메트릭 오류를 크게 줄인다.
자세 추정과 장소 인식이 결합되지만, 여전히 미리 구축된 맵 데이터베이스에 키프레임이나 장소가 필요하다.
따라서, Global pose estimation을 위해 글로벌맵만 필요한 one-stage 접근 방식을 살펴보자.
3-4. One-Stage Global Pose Estimation
3-3절과 같이, 장소 인식과 포즈 추정을 두 단계로 진행하는 방식이 성공적인 것으로 보아,
장소를 분리하지 않고 글로벌 맵에서 직접 global pose를 추정하는 방법이 제시되었고, 일부 접근 방식은 one-stage global pose estimation을 달성할 수 있다.
포즈를 추정하는 방법에 따라, 전통적인 closed form 혹은 end-to-end 방식으로 두 범주로 분류된다.
3-4-1. Feature-based Matching
SegMatch(Dube et al.)는 먼저 지면 제거를 통해 클러스터에 대해 dense LiDAR map point를 segment한 다음,
고유 값과 세그먼트 모양을 기반으로 특징을 추출한다.
이후, 랜덤 포레스트 분류기를 통해 훈련하여, 특징 매칭을 강화한다.
마지막으로, 매칭된 6-DOF pose estimation을 위해 RANSAC에 입력된다.
이러한 segment matching 기반의 접근 방식은 segment 결과에 의존하므로, 일부 특정 작업에서는 두 단계 접근 방식에 비해 덜 효율적일 수 있다.
3-4-2. Deep Regression
global robot pose를 직접 regression하는 방법을 제안하고 있다.
PoseNet을 통해 visual re-localization을 진행했으며,
PointLoc(Wang et al.)은 러닝 기반의 LiDAR global pose estimation을 제안하였다.
UPPNet은 포인트 등록 문제를 계층적으로 해결하며, 잠재적 하위 영역을 검색한 후 지역 특징 매칭을 통해 포즈 추정을 수행한다.
이러한 방법들은 지역적 특징이 아닌 전체 맵에서 부분적 지역 특징을 사용하기 때문에,
대규모 피쳐 맵에서의 re-localization이 어려운 단점을 가진다.
Deep Regression은 여전히 유명한 연구 방법이지만, end-to-end 방법의 해석 가능성과 일반화 능력을 향상시킬 필요가 있다.

이와 관련된 여러 가지 단일샷 글로벌 LiDAR Localization 사례가 표 1에 나와있으며,
3.1, 3.2, 3.3 절의 방법들은 일반적으로 KeyFrame 기반 SubMap에 의존한다. [7]
4. Sequential Global Localization
섹션 3에서는 단일 LiDAR 포인트 클라우드를 입력으로 사용하는 관련 single-shot global localization 방식을 검토했다.
섹션 1.1에서 이미 분석했듯이, 지도 크기 |M|은 단일 포인트 클라우드 |zi]의 크기보다 일반적으로 훨씬 크다.
반면에, single-shot global localization 기술은 localization 성공에 보장을 주지 못한다.
반면, LiDAR 센서는 높은 주기로 값을 주고,로봇이 이동할 때 순차적인 포인트 클라우드를 얻을 수 있습니다.
따라서, 여러 번의 측정을 수행하면, 로봇의 이동과 함께 global localization 성능을 향상시킬 수 있다.
따라서, 이 섹션에서는 global pose estimation을 위해 순차적인 LiDAR 입력을 사용하는 방법을 검토한다.

(1) Sequential Place Matching : localization 결과로 장소 인식을 제공하며, keyframe기반의 submap으로 구현된다.
(2) Sequential Metric Localization : metric map에서의 정확한 pose를 추정하고, global metric map에 기반한다.
섹션 1.1에서 분석했듯이, 우리는 순차 기반 접근 방식을 두가지 범주로 분류할 수 있다고 간주한다.
(1) 배치 처리 / (2) 재귀 필터링
글로벌 포즈 추정을 위해 순차적 정보를 어떻게 처리하는 지에 있다.
(1) 배치처리 : 전체 로봇 궤적을 추정하기 위해 retrieval과 optimization을 통해 정보를 배치로 다루는 것 (Eq. 4)
(2) 재귀 필터링 : 베이지안 필터링 또는 유사한 기법(Eq. 5)에서 포즈를 추정한다.
4-1. Sequential Place Matching on keyframe-based submaps
FAB-MAP은 먼저 단일 이미지 검색을 위한 외형 기반 BoW(Bag of Words)를 구축한 후,
global localization을 위한 재귀 베이시안 필터링을 공식화한다.
확장된 버전인 FAB-MAP 3D는 공간 정보를 모델링하여 프레임워크의 강건성을 향상시킨다.
이러한 FAB-MAP 계열은 순차적인 값의 처리가 가능하지만,
도전적인 장면에서 single-shot place recognition이 실패할 경우 쉽게 충돌합니다.
SeqSLAM (Milford & Wyeth, 2012)에서는 시퀀스 간 매칭 전략을 제안하여, 이미지 유사성 행렬에서 위치 후보를 찾는다.
SeqLPD(Liu et al., 2019)은 전방 장소 인식을 위해 LPD-Net(Liu et al., 2019)을 사용하고, 글로벌 위치 추정을 위한 거칠게-정밀한 시퀀스 매칭 전략을 설계할 것을 제안했습니다. 이 설계된 전략은 단일 샷 LPD-Net에 비해 장소 검색 성능을 향상시킵니다.
Yin 등(2022)은 SphereVLAD를 사용하여 생성된 순차적 장소 인식 결과를 기반으로 대규모 환경에서 입자 보조 빠른 매칭 방식을 제안합니다(Sect. 3.1.3)
상태 추정 관점에서, Liu 등(2019)은 배치 정보를 처리하는 반면 Yin 등(2022)은 위치를 재귀적으로 추정합니다.
최근의 연구인 SeqOT(Ma 등, 2022)은 이전 버전(Ma 등, 2022)의 여러 설명자 대신 범위 이미지 시퀀스를 위한 하나의 글로벌 설명자를 생성합니다. 구체적으로, 공간 및 시간 정보 융합을 처리하기 위해 새로운 엔드-투-엔드 트랜스포머가 설계되었습니다.
위에서 언급된 모든 방법, 시각적 또는 LiDAR 기반은 위상 키프레임 기반 서브맵(Sect. 2.1)에서 가장 가능성이 높은(최고 확률) 매치를 추정하는 것을 목표로 합니다. 이러한 방법들의 평가 방식은 섹션 3.1에서 장소 인식 전용 접근 방식과 동일합니다.
4-2. Sequential Metric Global Localization
맵이 Occupancy grids나 Landmarks와 같이 기하학적 표현을 가진다면,
metric pose estimation이 더 실용적인 global localization 방법이 될 수 있다.
파티클 필터(=MCL(Monte Carlo Localization))은 잘 알려진 재귀 state estimation back-end이다.
칼만 필터 계열과 달리, MCL은 로봇 상태의 분포를 가정하지 않는 non-parametric 베이지안 필터링이다.
구체적으로, MCL은 로봇 상태를 나타내기 위해 샘플 그룹을 사용하며,
로봇의 pose가 멀티모달 분포를 가질 때 global localization에 적합하다.
(*가우시안 분포를 가정한다면, 다수의 peak를 가질 수 없기 때문일 것이다.)
기존 MCL의 강건성과 효율성을 개선하기 위해 다양한 확장 버전이 제안되어 왔는데,
최근의 연구(Zimmerman et al., 2022)는 사람이 읽을 수 있는 텍스트 정보를 MCL에 통합하여, 건물의 구조적 변화에 더 강인하게 만들었습니다. 또한, 단순성과 효율성을 위해, MCL은 global localization 외에 robot pose traking (Yin et al., 2022) and exploration tasks (Stachniss et al., 2005)와 같은 다양한 저차원 내비게이션 작업에 사용된다.
현재 MCL은 여러 navigation 툴킷의 표준 중 하나이다.
특히, 최근 실내 LiDAR localization의 경향은 CAD를 맵으로 사용한다. (Boniardi et al., 2017; Zimmerman et al., 2023)
그리고 BIM(건축 정보 모델링)을 사용한 semantic building information modeling도 사용된다.
또, 저렴하게 만들 수 있는 평면도를 통해서도 로컬라이제이션에 사용될 수 있다. (Boniardi 등, 2017; Zimmerman 등, 2023).
이렇게 하면 sparse하지만 중요한 정보를 유지하면서 쉽게 얻을 수 있다.
이러한 맵의 사용은 장기 운영을 위해 미리 맵핑할 필요없이 localization을 가능하게 한다.
현대의 MCL 방법은 discrete place recognition + filtering 프레임워크로 대규모 실외 환경에 적용하도록 한다.
심층 학습 방법으로 인한 발전
- Yin et al. (2018)은 다수의 장소 인식 결과를 위해, Gaussian mixture model을 제안하였고, 측정 모델로서 MCL 시스템을 통합했다. MCL의 수렴으로 인해 정확한 ICP 정제를 위한 초기 추정을 생성할 수 있다.
- 방향의 가시성도 확장 버전(Yin 등, 2019)에서 증명되었다.
- Chen 등(2020)은 그들의 OverlapNet(Chen 등, 2020)을 사용하여 글로벌 맵에서 서브맵의 특징을 추출하고 현재 특징과 저장된 특징 간의 유사성을 비교하여 MCL을 위한 새로운 관측 모델을 제안했다.
- Sun 등(2020)과 Akai 등(2020)은 심층 포즈 회귀와 MCL을 융합하여 하이브리드 글로벌 위치 추정을 구축할 것을 제안했으며, 여기서 심층 포즈 회귀는 엔드-투-엔드 신경망에서 3자유도(DoF) 또는 6자유도를 제공할 수 있다.
위의 방법들(Yin 등, 2019; Chen 등, 2020; Sun 등, 2020; Akai 등, 2020)은 일반적으로 대규모 환경에서 MCL의 빠른 수렴을 위해 포즈 및 맵 공간을 이산화한다.
- Chen 등(2021)은 DSOM이라고 불리는 심층 학습 지원 샘플 가능한 관측 모델을 제안했으며, 2D 레이저 스캔과 글로벌 실내 맵이 주어지면 DSOM은 글로벌 맵에서 MCL을 위한 확률 분포를 제공하여 입자 샘플링을 높은 가능성 지역에 집중하게 한다.
- 로봇 포즈 추적 및 글로벌 위치 추정을 위한 미분 가능한 파티클 필터(DPF, Jonschkowskiet al. (2018)) 방식
전체 DPF 파이프라인은 미분 가능한 움직임 및 측정 모델과 입자에 대한 신념 업데이트 모델을 포함하여 DPF가 엔드-투-엔드 방식으로 훈련될 수 있게 만든다.
Differentiable SLAM-net(Karkus et al. (2021))에서는 DPF가 실내 로컬라이제이션을 위한 훈련 가능한 시각 SLAM으로 인코딩된다. LiDAR 기반 파티클 필터는 매우 성숙하며, 현재 LiDAR 기반 DPF는 존재하지 않지만, 미분 가능한 상태 추정기는 빅데이터 시대에서 유망한 방향일 수 있다고 생각한다.
그 외 프레임워크
Multiple Hypotheses Tracking(MHT, Thrun et al., 2005)은 글로벌 위치 추정 문제에 대한 가능한 해결책입니다.
Gao 등(2019)은 개선된 MHT 프레임워크를 제안하고, 저자들은 가설에 가중치를 부여하기 위해 새로운 구조적 단위 인코딩 방식을 설계했습니다.
Hendrikx 등(2022)은 실내 글로벌 위치 추정을 위해 가설 트리를 구축할 것을 제안했습니다. 이 방법에는 글로벌 피처 맵이 필요하며 명시적인 데이터 연관이 가설을 확인하는 데 사용됩니다.
Wang 등(2019)은 평면도를 이용한 요인 그래프 기반 글로벌 위치 추정을 제안했습니다(GLFP). GLFP는 로봇이 이동할 때 위치 추정에 오도메트리 정보와 랜드마크 매칭을 요인 그래프에 통합합니다.
필터링 계열(MCL 및 MHT)과 비교할 때, GLFP는 글로벌 포즈 추정을 위한 일괄 정보를 처리하며, 이는 섹션 4.1의 SeqSLAM과 유사합니다.
Wang 등(2019)에서의 랜드마크 매칭은 요인 그래프 최적화를 위한 글로벌 위치 정보를 제공합니다. Wilbers 등(2019)의 연구에서는 연구자들이 그래프 기반 슬라이딩 윈도우 접근법을 사용하여 실외 랜드마크 매칭과 오도메트리 정보를 융합합니다. 다른 센서 정보도 모바일 로봇을 위한 글로벌 위치를 제공할 수 있습니다.
Merfels와 Stachniss(2016)는 GNSS와 오도메트리 정보를 융합하여 자율 주행을 위한 자기 로컬라이제이션을 달성했습니다.
마지막으로, 이 하위 섹션에서는 일반적으로 루트 평균 제곱 오차(RMSE)를 사용하여 맵에서의 메트릭 포즈 추정을 포함하며, 이는 섹션 4.1의 접근법과 다릅니다.

5. LiDAR-aided Cross-robot Localization
한 로봇은 mapping을 수행하고, 다른 로봇은 이 맵에 대해서 전역적으로 자체의 pose 추정을 진행하며, 반대로 진행한다.
본 서베이에서 다루지 않는 부가문제들이 있다.

5-1. LiDAR-aided Multi-robot System
시스템 구조로부터, distributed 멀티로봇 시스템과 centralized server는 다른 시나리오에서 잘 작동할 수 있다.
커스텀된 스캔 매칭 (포인트 클라우드 맵 퓨전과 협동 로봇을 위해)(* Aerial-ground robots collaborative 3d mapping in gnss-denied environments)
이러한 기술은 offline 맵에 기반되고, 여기선 keyframe-based cross-robot localization에 집중한다.
prior maps이 없고 GNSS-denied되는 영역에서의 navigation으로 multi-robot SLAM이 관심을 받고 있다.
최근 2021년에 끝난 DARPA Subterranean 챌린지는 최첨단 mapping과 localization, 복잡한 지하 환경 탐색을 입증하고 발전하는 것, 그리고 멀티로봇 SLAM을 발전하는 것이 목표이다. (* 대회 내 멀티 로봇 SLAM 구조 서베이)
Present and Future of SLAM in Extreme Underground Environments
This paper reports on the state of the art in underground SLAM by discussing different SLAM strategies and results across six teams that participated in the three-year-long SubT competition. In particular, the paper has four main goals. First, we review th
arxiv.org
이전까지 제안된 loop closure method와 다르게, 많은 팀은 현재와 다른 keyframe 사이 거리를 'factor graph'를 계산하는 식으로 간단히 진행하였다.
* Factor graph
Factor graph
- 어떤 함수의 factorisation을 표현하는 이분 그래프(Bipartite Graph)
- Variable node와 Factor node로 이뤄진다.
로보틱스의 경우, Variable node는 로봇의 position 혹은 landmark의 position 등이 될 수 있다.
Factor node는 측정으로부터 계산된 constraint가 된다.
- 이를 이용해, Sum-product 문제를 풀 수 있다.
Sum-product 문제에는 belief propagation, Viterbi, Kalman filter, turbo-codes, fast Fourier transform 등 다양한 알고리즘이 있다.
Factor
Ensemble을 이루는 시스템의 각각의 상태값에 대한 함수로 정의됨.
주어진 Random Variable 집합 X가 MRF(Markov Random Field)를 형성한다면, 그에 해당하는 Undirected Graph(V, E)가 존재할 것이다.
이때 Factor 집합에 대하여 이분 그래프(Bipartite Graph) G=(V,F,E)를 그린다면 이 때의 Graph를 Factor Graph라 한다.
Bipartite Graph (이분 그래프)
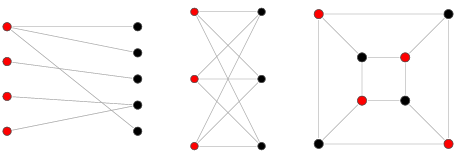
인접한 정점끼리 서로 다른 색으로 칠한다면, 모든 정점을 두 가지 색으로만 칠할 수 있는 그래프.
즉, 같은 그룹에 속한 정점끼리는 서로 인접하지 않는 그래프
이분 그래프인지 확인하는 방법은 BFS(너비 우선 탐색), DFS(깊이 우선 탐색)
-> 정점을 방문할 때마다 두 가지 색 중 하나로 칠한다. 다음 정점을 방문하면, 자신과 인접한 정점은 자신과 다른 색으로 칠한다. -> 탐색을 진행할 때 자신과 인접한 정점의 색이 자신과 동일하면 이분 그래프 X
SLAM에서 factor graph를 이용하는 방법

- 처음 로봇이 켜지면 아무런 정보가 없으므로, 센서를 통해 'landmark measruement'를 얻는다.
(카메라는 local feature의 픽셀 위치(SIFT, ORB)가 될 수 있고, 라이다에서는 3D point의 위치가 될 수 있다.)
- 로봇이 움직이며 본인의 운동량에 대한 정보를 얻는다.
(Wheel odometry /dead reckoning을 통한 IMUT 센서 값 / 카메라, 라이다 odometry를 통해이동한 거리에 대한 정보를 얻을 수 있다.)
- 로봇이 계속 움직이면서 새로운 landmark measurment를 갖게 되고, 새로운 landmark 정보를 계속 얻는다. (이때 오차가 점점 쌓인다.)
- 로봇이 이전에 보았던 landmark를 다시 보면, loop closure가 발동되어 이어진 모든 node/edge들이 최적화되어 오차를 해소할 수 있다.
위의 과정을 factor graph로 표현하면 아래와 같다.

variable node 사이에 factor node가 올라가 있는 형태가 아니다.
즉, x0과 l1이 하나의 m1이라는 edge로 이어져있는 것이 아니고, x0는 m1과 이어져있고, m1이 l1과 이어져 있다.
5-2. Cross-robot Back-end
위의 시스템[215, 206, 216, 207, 208]에서 로봇 간 LCD 방법은 대규모 환경에서 로봇 간 로컬라이제이션을 가능하게 한다는 결론을 내릴 수 있습니다. 그러나 어떤 LiDAR LCD 방법도 거짓 양성 없이 완벽한 루프 클로저를 제공할 수 없습니다. 거짓 양성은 추정 시스템을 불안정하고 부정확하게 만드는 이상치입니다. 보다 구체적으로, 거의 모든 크로스 로봇 로컬라이제이션 시스템은 그래프 최적화 프레임워크를 기반으로 구축됩니다[16, 17]. 이러한 거짓 양성은 포즈 노드 간에 일관성 없는 링크를 제공합니다.
이러한 조건에서 최적화는 올바른 솔루션으로 수렴되지 않을 수 있습니다.
이 문제는 LiDAR aided cross-localization뿐만 아니라, 다른 센서를 사용하는 다른 SLAM 관련 문제에도 존재합니다.
이 문제를 처리하는 방법에는 주로 두 가지가 있습니다.
(1) 최적화 전에 이상치 거부 모듈 또는 유사한 기술을 구축하는 것이고, (RANSAC)
(2) 그래프 최적화 중에 이상치의 영향을 줄일 수 있는 강력한 커널 또는 함수를 설계하는 것입니다.
(SCGP(Single-cluster graph partitioning) : 그래프에서 클러스터링을 통해 pairwise consistency set을 최종 결과로 추정)
2018년 Enqvist 등은 루프 클로저와 일관된 매핑을 위한 쌍별 일관성 극대화(PCM)[220]를 제시합니다. PCM은 먼저 서로의 모든 루프 클로저를 확인하여 이진 일관성 그래프를 구축합니다. 일관성 검사의 기준이 공식화됩니다
오도메트리 모듈과 루프 클로저의 변환을 기반으로 합니다.
PCM은 그래프 이론에서 최대 클리크 문제인 최대 쌍별 내부 일관성 집합을 추정하는 것을 목표로 합니다(TEASER [49]에서 언급한 것과 동일한 문제, 섹션 3.2 참조).
팻타비라만 등[221]의 빠른 클리크 솔버는 PCM[220]에 채택되었습니다. PCM은 앞서 언급한 LiDAR 지원 교차 로봇 위치 파악 시스템[206, 207]과 기타 로봇 위치 파악 및 매핑 시스템[222, 223]에서 최근 몇 년 동안 검증되었습니다.
특이치 거부에도 불구하고 다른 방법은 포즈 그래프 최적화 중에 잘못된 루프의 영향을 줄이는 것입니다.
S ¨underhauf와 Protzel[224]은 최적화에서 전환 가능한 제약 조건을 공식화합니다.
추가된 제약 조건은 서로 다른 특이치 거부 정책을 따르며 루프 폐쇄를 켜거나 끌 수 있습니다. 반복적인 접근 방식 RRR은 [225]에서 설계되었으며 클러스터링 일관된 루프 폐쇄를 통해 진정한 긍정을 식별합니다. 이러한 강력한 기능은 일반적으로 포즈 그래프 최적화 프레임워크에 통합되어 개선됩니다
견고성 [16, 17]. 연구자들은 루프 에지를 식별하는 것 외에도 Gemen-McClure 커널[226]과 같은 강력한 커널을 최적화에 설계하고 사용합니다,
휴버 커널[226]과 맥스-믹스트 커널[227]. 2023년, 맥간 외(228)는 다음에서 점진적인 비볼록성 기법[119]을 활용하는 riSAM을 제시합니다
포즈 그래프 최적화. riSAM은 다른 강력한 추정 기법에 비해 더 나은 성능을 달성합니다. 실제 응용 분야에서는 이상치 거부와 강력한 추정기를 결합하여 사용하는 것이 거짓 양성을 처리하는 실용적인 선택이 될 수 있다고 생각합니다
루프 폐쇄.
요약하면, 크로스 로봇 로컬라이제이션은 향후 연구의 유망한 방향이 되고 있습니다. 주행 거리 측정, LCD, 백엔드 강건 추정기와 같은 로봇 공학의 여러 주제가 포함되어 있습니다. 크로스 로봇 로컬라이제이션 주제는 자율 주행 자동차를 위한 크라우드소싱 매핑[229]과 밀접한 관련이 있으며, 이는 이 조사의 범위를 벗어난 다른 중요한 주제와 관련이 있습니다.
6. Open Problems
6-1. Evaluation Difference
6-2. Multiple Modalities
최신 모바일 로봇에는 자체 로컬라이제이션을 위한 여러 센서가 장착되어 있습니다[246].
최근 몇 년 동안 멀티모달 감지는 커뮤니티에서 뜨거운 주제이며 많은 연구 관심을 받고 있습니다.
다양한 양식은 교차 모달 글로벌 로컬라이제이션에 직접적인 문제를 야기합니다.
그러나 반면에 각 센서 양식에는 장단점이 있으며 센서 양식 융합은 잠재적으로 로컬라이제이션의 신뢰성과 견고성을 향상시킬 수 있습니다.
최전선의 센서 양식에도 불구하고 최근의 학습 기술은 모달리티를 가능하게 합니다
더 높은 수준의 작업을 연구하고 LiDAR 글로벌 현지화 문제에 높은 수준의 의미론도 도입할 것입니다.
6-3. Less Overlap
6-4. Unbalanced Matching
6-5. Efficiency and Scalability
6-6. Generalization Ability
Sensor Configuration
Unseen Environments
Trigger of Global Localization
7. Conclusion
LiDAR Localization 관련해서 서칭하다가, 이 분야 유명하신 학자가 포함된 survey를 발견해서, 이를 토대로 견식을 쌓고자 한다!
이 글은 학부생이 공부를 목적으로 작성한 요약, 정리이므로,
오타 혹은 바로잡을 사항이 있다면, 언제든 코멘트는 환영입니다!
Contents
1. Introduction
1-1. Problem Formulation and Paper Organization
1-2. Typical Situations
1-3. Relationship to Previous Surveys
2. Maps for Global Localization
2-1. Keyframe-based Submap
2-2. Global Feature Map
2-3. Global Metric Map
3. Single-shot Global Localization: Place Recognition and Pose Estimation
3-1. Place Recognition Only
3-2. Place Recognition Followed by Local Pose Estimation
3-3. Pose Estimation-coupled Place Recognition
3-4. One-stage Global Pose Estimation
4. Sequential Global Localization
4-1. Sequential Place Matching
4-2. Sequential Metric Localization
5. LiDAR-aided Cross-robot Localization
5-1. LiDAR-aided Multi-robot System
5-2. Cross-robot Back-end
6. Open Problems
6-1. Evaluation Difference
6-2. Multiple Modalities
6-3. Less Overlap
6-4. Unbalanced Matching
6-5. Efficiency and Scalability
6-6. Generalization Ability
7. Conclusion
2. Maps for Global Localization
Global Localization을 위한 지도를 소개하며,
일반적으로 사용되는 지도를 3가지 기본 클러스터로 분류('키프레임 기반 서브맵, 글로벌 피쳐 맵, 글로벌 매트릭 맵)하여 설명
2-1. Keyframe-based Submap
대규모 환경에서 특히 사용,
각 키프레임은 '로봇의 포즈'와 '정렬된 서브맵', 그리고 키프레임 간의 topological 혹은 geometrical 연결 형태의 추가 정보로 구성된다.
Keyframe-based submap은 유지하기 쉽고, downstream navigation task(* 최종 해결하고자 하는 작업)에 적합하다.
2-2. Global Feature Map
환경을 설명하기 위해, sparse한 local feature point를 유지하며, HD map과 같은 방법을 통해 자율주행차량에 사용된다.
2-3. Global Metric Map
밀집된 metric 표현으로, 작업 환경을 설명하며, 이는 자원 제약이 있는 모바일 로봇에게는 부담이 될 수 있다.
3. Single-shot Global Localization: Place Recognition and Pose Estimation
3-1. Place Recognition Only
장소 인식만으로 가장 유사한 장소를 검색하는 방법을 다룬다.
3-1-1. Dense Points or Voxels-based
장소 인식만으로 접근하는 방식은 사전에 구축된 KeyFrame 기반의 Map에서 장소를 추출하여, 전역 위치 지정 문제를 해결한다.
LiDAR 장소 인식에서의 가장 큰 과제는 'global descriptor' 추출로, 이는 원시 point Cloud가 텍스처가 없고 불규칙하여 처리하기 어렵기 때문이다.
Dense Points or Voxels-based 방법은 밀집된 표현에서 직접 global descriptor를 생성하며, 초기 laser scanner는 로봇 위치 지정을 위해 2D laser point만 제공한다. ?
3D Point cloud 작업을 위한 PointNet과 같은 새로운 인코더는 성능 향상을 가져왔고,
Transformer 구조가 등장하면서, 장소 인식에서 중요한 지역 특성을 선택하는 데 주목받고 있다.
또한, 3D Point cloud를 정규화하기 위해 복셀화 절차를 사용하여 전역 설명자를 추출하는 과정도 보편화되고 있다. [8]
3-1-2. Sparse Segements-based
포인트 세그먼트를 기반으로 장소 인식을 수행하는 방법이다.
Seed는 원시 Point Cloud를 segment 객체로 나누고, 이 객체의 위상적 정보를 서술자에 인코딩한다.
SGPR은 원시 Point Cloud의 의미론적 및 위상적 정보를 활용하여, 그래프 신경망을 사용해 의미 그래프 표현을 생성한다.
Locus는 일시적이고 위상적인 정보를 인코딩해서, 구별 가능한 장면 표현을 만든다.
이러한 segementation기반의 접근 방식은 인간의 장소 인식 방법에 가까우며, 고수준 표현을 사용하는 경향이 있다.
따라서, segementation의 품질과 추가적인 의미 정보에 크게 의존하며, 3D Point Cloud segementation은 보통 시간과 자원을 많이 소모한다. [9]
3-1-3. Projection-based
3D Point Cloud를 2D 평면에 사영시킨 후, global descriptor를 추출한다.
M2DP(He et al.)은 원시 포인트 클라우드를 여러 2D 평면에 사영하여, 다양한 평면의 descriptor로 시그니처를 구성한다.
LiDAR Iris는 3D 포인트 클라우드의 높이 정보를 이진 LiDAR-Iris 이미지로 인코딩하고, 회전 불변성을 달성하기 위해 Fourier domain으로 변환한다.
Kong et al.은 포인트 클라우드를 의미 정보로 인코딩된 scan context 이미지로 변환하고, 회전 불변 표현을 학습하기 위한 네트워크를 설계했다.
전반적으로, 3D LiDAR 포인트 클라우드의 global descriptor 추출이 성공적인 수준에 도달했지만, 일반화 능력 등의 여러 과제가 남아있다. (6.6절)
3-2. Place Recognition Followed by Local Pose Estimation
장소 인식 후에, 로봇의 자세를 사용자 맞춤형 자세 추정기를 통해 추정하는 방법을 설명한다.
고정밀 변환 추정을 위한 로컬 포즈 추정 방법을 다룬다.
장소 인식과 독립적으로 수행되며, 전체 로컬라이제이션은 거친 방법에서 세밀한 방법으로 진행된다.
먼저, 키프레임 기반의 서브맵에서 장소 검색을 수행하고,
입력 LiDAR를 매핑 데이터에 맞춰 로컬 포즈 추정을 적용한다.
local pose estimation은 일반적으로 정확한 포인트 클라우드 등록을 통해 이루어지며,
포인트 클라우드 등록(Point cloud registration = scan matching)은 로보틱스와 컴퓨터비전에 인기있는 토픽으로, 오류 함수를 최소화하여 최적의 변환을 추정하는 것을 목표로 한다.
3-2-1. Correspondence-based
포인트 클라우드 정합의 Challenge와 해결 방법
ICP 알고리즘은 계산 효율성에도 불구하고, 노이즈와 외부 요인에 취약한 것으로 알려져있다.
Go-ICP는 글로벌 정합을 제공하지만, 리소스 한계가 있는 플랫폼에서는 비효율적이다.
최근 연구는 LiDAR와 2D image 기반 특징 추출에 집중하며, 딥러닝 기반 기법들이 주목을 받고 있다.
RANSAC 등의 방법이 외부요인을 극복하는 데 사용되며, TEASER와 같은 방법은 높은 신뢰성을 보인다.
특징 기반 및 강건한 추정자가 결합된 방법들이 정밀한 위치 추정을 가능하게 한다.
3-2-2. Correspondence-free
3-3. Pose Estimation-coupled Place Recognition
장소 인식과 자세 추정을 밀접하게 결합한 방법을 다루는데,
구체적으로 동일한 처리 파이프라인을 공유하여, 맵을 더 간결하고 파이프라인을 더욱 긴밀하게 만들어 준다.
3-3-1. 3-DOF pose stimation
3-DOF pose estimation은 주로 평면 표면에서 작동하는 모바일 로봇에 초점을 맞추며, 위치와 yaw 값을 포함한다.
이를 위해 다양한 방법론들이 제안되었는데, 특히 Scan Context++와 함께 세부적으로 향상시키기 위한 기법들이 있다.
또한, range 이미지의 오버랩 추정 및 향상된 효율성을 제공하는 여러 방법이 논의되었으며, 이는 3-DoF pose estimation에 중요한 역할을 한다. [13]
3-3-2. 6-DOF pose stimation
* 장소 검색을 사용하는 이전 2단계 파이프라인(3.1.)에 이어, 정밀한 포즈 추정(3.2.)에 이어 이 방법의 장점은 무엇인가?
(1) Lightweight map
(2) Geometric verification
(3) Initial guess for refinement : LCDNet에 따르면, 초기 추정은 ICP 등록 적용시 런타임과 메트릭 오류를 크게 줄인다.
자세 추정과 장소 인식이 결합되지만, 여전히 미리 구축된 맵 데이터베이스에 키프레임이나 장소가 필요하다.
따라서, Global pose estimation을 위해 글로벌맵만 필요한 one-stage 접근 방식을 살펴보자.
3-4. One-Stage Global Pose Estimation
3-3절과 같이, 장소 인식과 포즈 추정을 두 단계로 진행하는 방식이 성공적인 것으로 보아,
장소를 분리하지 않고 글로벌 맵에서 직접 global pose를 추정하는 방법이 제시되었고, 일부 접근 방식은 one-stage global pose estimation을 달성할 수 있다.
포즈를 추정하는 방법에 따라, 전통적인 closed form 혹은 end-to-end 방식으로 두 범주로 분류된다.
3-4-1. Feature-based Matching
SegMatch(Dube et al.)는 먼저 지면 제거를 통해 클러스터에 대해 dense LiDAR map point를 segment한 다음,
고유 값과 세그먼트 모양을 기반으로 특징을 추출한다.
이후, 랜덤 포레스트 분류기를 통해 훈련하여, 특징 매칭을 강화한다.
마지막으로, 매칭된 6-DOF pose estimation을 위해 RANSAC에 입력된다.
이러한 segment matching 기반의 접근 방식은 segment 결과에 의존하므로, 일부 특정 작업에서는 두 단계 접근 방식에 비해 덜 효율적일 수 있다.
3-4-2. Deep Regression
global robot pose를 직접 regression하는 방법을 제안하고 있다.
PoseNet을 통해 visual re-localization을 진행했으며,
PointLoc(Wang et al.)은 러닝 기반의 LiDAR global pose estimation을 제안하였다.
UPPNet은 포인트 등록 문제를 계층적으로 해결하며, 잠재적 하위 영역을 검색한 후 지역 특징 매칭을 통해 포즈 추정을 수행한다.
이러한 방법들은 지역적 특징이 아닌 전체 맵에서 부분적 지역 특징을 사용하기 때문에,
대규모 피쳐 맵에서의 re-localization이 어려운 단점을 가진다.
Deep Regression은 여전히 유명한 연구 방법이지만, end-to-end 방법의 해석 가능성과 일반화 능력을 향상시킬 필요가 있다.
이와 관련된 여러 가지 단일샷 글로벌 LiDAR Localization 사례가 표 1에 나와있으며,
3.1, 3.2, 3.3 절의 방법들은 일반적으로 KeyFrame 기반 SubMap에 의존한다. [7]
4. Sequential Global Localization
섹션 3에서는 단일 LiDAR 포인트 클라우드를 입력으로 사용하는 관련 single-shot global localization 방식을 검토했다.
섹션 1.1에서 이미 분석했듯이, 지도 크기 |M|은 단일 포인트 클라우드 |zi]의 크기보다 일반적으로 훨씬 크다.
반면에, single-shot global localization 기술은 localization 성공에 보장을 주지 못한다.
반면, LiDAR 센서는 높은 주기로 값을 주고,로봇이 이동할 때 순차적인 포인트 클라우드를 얻을 수 있습니다.
따라서, 여러 번의 측정을 수행하면, 로봇의 이동과 함께 global localization 성능을 향상시킬 수 있다.
따라서, 이 섹션에서는 global pose estimation을 위해 순차적인 LiDAR 입력을 사용하는 방법을 검토한다.
(1) Sequential Place Matching : localization 결과로 장소 인식을 제공하며, keyframe기반의 submap으로 구현된다.
(2) Sequential Metric Localization : metric map에서의 정확한 pose를 추정하고, global metric map에 기반한다.
섹션 1.1에서 분석했듯이, 우리는 순차 기반 접근 방식을 두가지 범주로 분류할 수 있다고 간주한다.
(1) 배치 처리 / (2) 재귀 필터링
글로벌 포즈 추정을 위해 순차적 정보를 어떻게 처리하는 지에 있다.
(1) 배치처리 : 전체 로봇 궤적을 추정하기 위해 retrieval과 optimization을 통해 정보를 배치로 다루는 것 (Eq. 4)
(2) 재귀 필터링 : 베이지안 필터링 또는 유사한 기법(Eq. 5)에서 포즈를 추정한다.
4-1. Sequential Place Matching on keyframe-based submaps
FAB-MAP은 먼저 단일 이미지 검색을 위한 외형 기반 BoW(Bag of Words)를 구축한 후,
global localization을 위한 재귀 베이시안 필터링을 공식화한다.
확장된 버전인 FAB-MAP 3D는 공간 정보를 모델링하여 프레임워크의 강건성을 향상시킨다.
이러한 FAB-MAP 계열은 순차적인 값의 처리가 가능하지만,
도전적인 장면에서 single-shot place recognition이 실패할 경우 쉽게 충돌합니다.
SeqSLAM (Milford & Wyeth, 2012)에서는 시퀀스 간 매칭 전략을 제안하여, 이미지 유사성 행렬에서 위치 후보를 찾는다.
SeqLPD(Liu et al., 2019)은 전방 장소 인식을 위해 LPD-Net(Liu et al., 2019)을 사용하고, 글로벌 위치 추정을 위한 거칠게-정밀한 시퀀스 매칭 전략을 설계할 것을 제안했습니다. 이 설계된 전략은 단일 샷 LPD-Net에 비해 장소 검색 성능을 향상시킵니다.
Yin 등(2022)은 SphereVLAD를 사용하여 생성된 순차적 장소 인식 결과를 기반으로 대규모 환경에서 입자 보조 빠른 매칭 방식을 제안합니다(Sect. 3.1.3)
상태 추정 관점에서, Liu 등(2019)은 배치 정보를 처리하는 반면 Yin 등(2022)은 위치를 재귀적으로 추정합니다.
최근의 연구인 SeqOT(Ma 등, 2022)은 이전 버전(Ma 등, 2022)의 여러 설명자 대신 범위 이미지 시퀀스를 위한 하나의 글로벌 설명자를 생성합니다. 구체적으로, 공간 및 시간 정보 융합을 처리하기 위해 새로운 엔드-투-엔드 트랜스포머가 설계되었습니다.
위에서 언급된 모든 방법, 시각적 또는 LiDAR 기반은 위상 키프레임 기반 서브맵(Sect. 2.1)에서 가장 가능성이 높은(최고 확률) 매치를 추정하는 것을 목표로 합니다. 이러한 방법들의 평가 방식은 섹션 3.1에서 장소 인식 전용 접근 방식과 동일합니다.
4-2. Sequential Metric Global Localization
맵이 Occupancy grids나 Landmarks와 같이 기하학적 표현을 가진다면,
metric pose estimation이 더 실용적인 global localization 방법이 될 수 있다.
파티클 필터(=MCL(Monte Carlo Localization))은 잘 알려진 재귀 state estimation back-end이다.
칼만 필터 계열과 달리, MCL은 로봇 상태의 분포를 가정하지 않는 non-parametric 베이지안 필터링이다.
구체적으로, MCL은 로봇 상태를 나타내기 위해 샘플 그룹을 사용하며,
로봇의 pose가 멀티모달 분포를 가질 때 global localization에 적합하다.
(*가우시안 분포를 가정한다면, 다수의 peak를 가질 수 없기 때문일 것이다.)
기존 MCL의 강건성과 효율성을 개선하기 위해 다양한 확장 버전이 제안되어 왔는데,
최근의 연구(Zimmerman et al., 2022)는 사람이 읽을 수 있는 텍스트 정보를 MCL에 통합하여, 건물의 구조적 변화에 더 강인하게 만들었습니다. 또한, 단순성과 효율성을 위해, MCL은 global localization 외에 robot pose traking (Yin et al., 2022) and exploration tasks (Stachniss et al., 2005)와 같은 다양한 저차원 내비게이션 작업에 사용된다.
현재 MCL은 여러 navigation 툴킷의 표준 중 하나이다.
특히, 최근 실내 LiDAR localization의 경향은 CAD를 맵으로 사용한다. (Boniardi et al., 2017; Zimmerman et al., 2023)
그리고 BIM(건축 정보 모델링)을 사용한 semantic building information modeling도 사용된다.
또, 저렴하게 만들 수 있는 평면도를 통해서도 로컬라이제이션에 사용될 수 있다. (Boniardi 등, 2017; Zimmerman 등, 2023).
이렇게 하면 sparse하지만 중요한 정보를 유지하면서 쉽게 얻을 수 있다.
이러한 맵의 사용은 장기 운영을 위해 미리 맵핑할 필요없이 localization을 가능하게 한다.
현대의 MCL 방법은 discrete place recognition + filtering 프레임워크로 대규모 실외 환경에 적용하도록 한다.
심층 학습 방법으로 인한 발전
- Yin et al. (2018)은 다수의 장소 인식 결과를 위해, Gaussian mixture model을 제안하였고, 측정 모델로서 MCL 시스템을 통합했다. MCL의 수렴으로 인해 정확한 ICP 정제를 위한 초기 추정을 생성할 수 있다.
- 방향의 가시성도 확장 버전(Yin 등, 2019)에서 증명되었다.
- Chen 등(2020)은 그들의 OverlapNet(Chen 등, 2020)을 사용하여 글로벌 맵에서 서브맵의 특징을 추출하고 현재 특징과 저장된 특징 간의 유사성을 비교하여 MCL을 위한 새로운 관측 모델을 제안했다.
- Sun 등(2020)과 Akai 등(2020)은 심층 포즈 회귀와 MCL을 융합하여 하이브리드 글로벌 위치 추정을 구축할 것을 제안했으며, 여기서 심층 포즈 회귀는 엔드-투-엔드 신경망에서 3자유도(DoF) 또는 6자유도를 제공할 수 있다.
위의 방법들(Yin 등, 2019; Chen 등, 2020; Sun 등, 2020; Akai 등, 2020)은 일반적으로 대규모 환경에서 MCL의 빠른 수렴을 위해 포즈 및 맵 공간을 이산화한다.
- Chen 등(2021)은 DSOM이라고 불리는 심층 학습 지원 샘플 가능한 관측 모델을 제안했으며, 2D 레이저 스캔과 글로벌 실내 맵이 주어지면 DSOM은 글로벌 맵에서 MCL을 위한 확률 분포를 제공하여 입자 샘플링을 높은 가능성 지역에 집중하게 한다.
- 로봇 포즈 추적 및 글로벌 위치 추정을 위한 미분 가능한 파티클 필터(DPF, Jonschkowskiet al. (2018)) 방식
전체 DPF 파이프라인은 미분 가능한 움직임 및 측정 모델과 입자에 대한 신념 업데이트 모델을 포함하여 DPF가 엔드-투-엔드 방식으로 훈련될 수 있게 만든다.
Differentiable SLAM-net(Karkus et al. (2021))에서는 DPF가 실내 로컬라이제이션을 위한 훈련 가능한 시각 SLAM으로 인코딩된다. LiDAR 기반 파티클 필터는 매우 성숙하며, 현재 LiDAR 기반 DPF는 존재하지 않지만, 미분 가능한 상태 추정기는 빅데이터 시대에서 유망한 방향일 수 있다고 생각한다.
그 외 프레임워크
Multiple Hypotheses Tracking(MHT, Thrun et al., 2005)은 글로벌 위치 추정 문제에 대한 가능한 해결책입니다.
Gao 등(2019)은 개선된 MHT 프레임워크를 제안하고, 저자들은 가설에 가중치를 부여하기 위해 새로운 구조적 단위 인코딩 방식을 설계했습니다.
Hendrikx 등(2022)은 실내 글로벌 위치 추정을 위해 가설 트리를 구축할 것을 제안했습니다. 이 방법에는 글로벌 피처 맵이 필요하며 명시적인 데이터 연관이 가설을 확인하는 데 사용됩니다.
Wang 등(2019)은 평면도를 이용한 요인 그래프 기반 글로벌 위치 추정을 제안했습니다(GLFP). GLFP는 로봇이 이동할 때 위치 추정에 오도메트리 정보와 랜드마크 매칭을 요인 그래프에 통합합니다.
필터링 계열(MCL 및 MHT)과 비교할 때, GLFP는 글로벌 포즈 추정을 위한 일괄 정보를 처리하며, 이는 섹션 4.1의 SeqSLAM과 유사합니다.
Wang 등(2019)에서의 랜드마크 매칭은 요인 그래프 최적화를 위한 글로벌 위치 정보를 제공합니다. Wilbers 등(2019)의 연구에서는 연구자들이 그래프 기반 슬라이딩 윈도우 접근법을 사용하여 실외 랜드마크 매칭과 오도메트리 정보를 융합합니다. 다른 센서 정보도 모바일 로봇을 위한 글로벌 위치를 제공할 수 있습니다.
Merfels와 Stachniss(2016)는 GNSS와 오도메트리 정보를 융합하여 자율 주행을 위한 자기 로컬라이제이션을 달성했습니다.
마지막으로, 이 하위 섹션에서는 일반적으로 루트 평균 제곱 오차(RMSE)를 사용하여 맵에서의 메트릭 포즈 추정을 포함하며, 이는 섹션 4.1의 접근법과 다릅니다.
5. LiDAR-aided Cross-robot Localization
한 로봇은 mapping을 수행하고, 다른 로봇은 이 맵에 대해서 전역적으로 자체의 pose 추정을 진행하며, 반대로 진행한다.
본 서베이에서 다루지 않는 부가문제들이 있다.
5-1. LiDAR-aided Multi-robot System
시스템 구조로부터, distributed 멀티로봇 시스템과 centralized server는 다른 시나리오에서 잘 작동할 수 있다.
커스텀된 스캔 매칭 (포인트 클라우드 맵 퓨전과 협동 로봇을 위해)(* Aerial-ground robots collaborative 3d mapping in gnss-denied environments)
이러한 기술은 offline 맵에 기반되고, 여기선 keyframe-based cross-robot localization에 집중한다.
prior maps이 없고 GNSS-denied되는 영역에서의 navigation으로 multi-robot SLAM이 관심을 받고 있다.
최근 2021년에 끝난 DARPA Subterranean 챌린지는 최첨단 mapping과 localization, 복잡한 지하 환경 탐색을 입증하고 발전하는 것, 그리고 멀티로봇 SLAM을 발전하는 것이 목표이다. (* 대회 내 멀티 로봇 SLAM 구조 서베이)
Present and Future of SLAM in Extreme Underground Environments
This paper reports on the state of the art in underground SLAM by discussing different SLAM strategies and results across six teams that participated in the three-year-long SubT competition. In particular, the paper has four main goals. First, we review th
arxiv.org
이전까지 제안된 loop closure method와 다르게, 많은 팀은 현재와 다른 keyframe 사이 거리를 'factor graph'를 계산하는 식으로 간단히 진행하였다.
* Factor graph
Factor graph
- 어떤 함수의 factorisation을 표현하는 이분 그래프(Bipartite Graph)
- Variable node와 Factor node로 이뤄진다.
로보틱스의 경우, Variable node는 로봇의 position 혹은 landmark의 position 등이 될 수 있다.
Factor node는 측정으로부터 계산된 constraint가 된다.
- 이를 이용해, Sum-product 문제를 풀 수 있다.
Sum-product 문제에는 belief propagation, Viterbi, Kalman filter, turbo-codes, fast Fourier transform 등 다양한 알고리즘이 있다.
Factor
Ensemble을 이루는 시스템의 각각의 상태값에 대한 함수로 정의됨.
주어진 Random Variable 집합 X가 MRF(Markov Random Field)를 형성한다면, 그에 해당하는 Undirected Graph(V, E)가 존재할 것이다.
이때 Factor 집합에 대하여 이분 그래프(Bipartite Graph) G=(V,F,E)를 그린다면 이 때의 Graph를 Factor Graph라 한다.
Bipartite Graph (이분 그래프)
인접한 정점끼리 서로 다른 색으로 칠한다면, 모든 정점을 두 가지 색으로만 칠할 수 있는 그래프.
즉, 같은 그룹에 속한 정점끼리는 서로 인접하지 않는 그래프
이분 그래프인지 확인하는 방법은 BFS(너비 우선 탐색), DFS(깊이 우선 탐색)
-> 정점을 방문할 때마다 두 가지 색 중 하나로 칠한다. 다음 정점을 방문하면, 자신과 인접한 정점은 자신과 다른 색으로 칠한다. -> 탐색을 진행할 때 자신과 인접한 정점의 색이 자신과 동일하면 이분 그래프 X
SLAM에서 factor graph를 이용하는 방법
- 처음 로봇이 켜지면 아무런 정보가 없으므로, 센서를 통해 'landmark measruement'를 얻는다.
(카메라는 local feature의 픽셀 위치(SIFT, ORB)가 될 수 있고, 라이다에서는 3D point의 위치가 될 수 있다.)
- 로봇이 움직이며 본인의 운동량에 대한 정보를 얻는다.
(Wheel odometry /dead reckoning을 통한 IMUT 센서 값 / 카메라, 라이다 odometry를 통해이동한 거리에 대한 정보를 얻을 수 있다.)
- 로봇이 계속 움직이면서 새로운 landmark measurment를 갖게 되고, 새로운 landmark 정보를 계속 얻는다. (이때 오차가 점점 쌓인다.)
- 로봇이 이전에 보았던 landmark를 다시 보면, loop closure가 발동되어 이어진 모든 node/edge들이 최적화되어 오차를 해소할 수 있다.
위의 과정을 factor graph로 표현하면 아래와 같다.
variable node 사이에 factor node가 올라가 있는 형태가 아니다.
즉, x0과 l1이 하나의 m1이라는 edge로 이어져있는 것이 아니고, x0는 m1과 이어져있고, m1이 l1과 이어져 있다.
5-2. Cross-robot Back-end
위의 시스템[215, 206, 216, 207, 208]에서 로봇 간 LCD 방법은 대규모 환경에서 로봇 간 로컬라이제이션을 가능하게 한다는 결론을 내릴 수 있습니다. 그러나 어떤 LiDAR LCD 방법도 거짓 양성 없이 완벽한 루프 클로저를 제공할 수 없습니다. 거짓 양성은 추정 시스템을 불안정하고 부정확하게 만드는 이상치입니다. 보다 구체적으로, 거의 모든 크로스 로봇 로컬라이제이션 시스템은 그래프 최적화 프레임워크를 기반으로 구축됩니다[16, 17]. 이러한 거짓 양성은 포즈 노드 간에 일관성 없는 링크를 제공합니다.
이러한 조건에서 최적화는 올바른 솔루션으로 수렴되지 않을 수 있습니다.
이 문제는 LiDAR aided cross-localization뿐만 아니라, 다른 센서를 사용하는 다른 SLAM 관련 문제에도 존재합니다.
이 문제를 처리하는 방법에는 주로 두 가지가 있습니다.
(1) 최적화 전에 이상치 거부 모듈 또는 유사한 기술을 구축하는 것이고, (RANSAC)
(2) 그래프 최적화 중에 이상치의 영향을 줄일 수 있는 강력한 커널 또는 함수를 설계하는 것입니다.
(SCGP(Single-cluster graph partitioning) : 그래프에서 클러스터링을 통해 pairwise consistency set을 최종 결과로 추정)
2018년 Enqvist 등은 루프 클로저와 일관된 매핑을 위한 쌍별 일관성 극대화(PCM)[220]를 제시합니다. PCM은 먼저 서로의 모든 루프 클로저를 확인하여 이진 일관성 그래프를 구축합니다. 일관성 검사의 기준이 공식화됩니다
오도메트리 모듈과 루프 클로저의 변환을 기반으로 합니다.
PCM은 그래프 이론에서 최대 클리크 문제인 최대 쌍별 내부 일관성 집합을 추정하는 것을 목표로 합니다(TEASER [49]에서 언급한 것과 동일한 문제, 섹션 3.2 참조).
팻타비라만 등[221]의 빠른 클리크 솔버는 PCM[220]에 채택되었습니다. PCM은 앞서 언급한 LiDAR 지원 교차 로봇 위치 파악 시스템[206, 207]과 기타 로봇 위치 파악 및 매핑 시스템[222, 223]에서 최근 몇 년 동안 검증되었습니다.
특이치 거부에도 불구하고 다른 방법은 포즈 그래프 최적화 중에 잘못된 루프의 영향을 줄이는 것입니다.
S ¨underhauf와 Protzel[224]은 최적화에서 전환 가능한 제약 조건을 공식화합니다.
추가된 제약 조건은 서로 다른 특이치 거부 정책을 따르며 루프 폐쇄를 켜거나 끌 수 있습니다. 반복적인 접근 방식 RRR은 [225]에서 설계되었으며 클러스터링 일관된 루프 폐쇄를 통해 진정한 긍정을 식별합니다. 이러한 강력한 기능은 일반적으로 포즈 그래프 최적화 프레임워크에 통합되어 개선됩니다
견고성 [16, 17]. 연구자들은 루프 에지를 식별하는 것 외에도 Gemen-McClure 커널[226]과 같은 강력한 커널을 최적화에 설계하고 사용합니다,
휴버 커널[226]과 맥스-믹스트 커널[227]. 2023년, 맥간 외(228)는 다음에서 점진적인 비볼록성 기법[119]을 활용하는 riSAM을 제시합니다
포즈 그래프 최적화. riSAM은 다른 강력한 추정 기법에 비해 더 나은 성능을 달성합니다. 실제 응용 분야에서는 이상치 거부와 강력한 추정기를 결합하여 사용하는 것이 거짓 양성을 처리하는 실용적인 선택이 될 수 있다고 생각합니다
루프 폐쇄.
요약하면, 크로스 로봇 로컬라이제이션은 향후 연구의 유망한 방향이 되고 있습니다. 주행 거리 측정, LCD, 백엔드 강건 추정기와 같은 로봇 공학의 여러 주제가 포함되어 있습니다. 크로스 로봇 로컬라이제이션 주제는 자율 주행 자동차를 위한 크라우드소싱 매핑[229]과 밀접한 관련이 있으며, 이는 이 조사의 범위를 벗어난 다른 중요한 주제와 관련이 있습니다.
6. Open Problems
6-1. Evaluation Difference
6-2. Multiple Modalities
최신 모바일 로봇에는 자체 로컬라이제이션을 위한 여러 센서가 장착되어 있습니다[246].
최근 몇 년 동안 멀티모달 감지는 커뮤니티에서 뜨거운 주제이며 많은 연구 관심을 받고 있습니다.
다양한 양식은 교차 모달 글로벌 로컬라이제이션에 직접적인 문제를 야기합니다.
그러나 반면에 각 센서 양식에는 장단점이 있으며 센서 양식 융합은 잠재적으로 로컬라이제이션의 신뢰성과 견고성을 향상시킬 수 있습니다.
최전선의 센서 양식에도 불구하고 최근의 학습 기술은 모달리티를 가능하게 합니다
더 높은 수준의 작업을 연구하고 LiDAR 글로벌 현지화 문제에 높은 수준의 의미론도 도입할 것입니다.
6-3. Less Overlap
6-4. Unbalanced Matching
6-5. Efficiency and Scalability
6-6. Generalization Ability
Sensor Configuration
Unseen Environments
Trigger of Global Localization
7. Conclusion